
MySQL es un SGBD multiusuario y multihilo
con aproximadamente 6 millones de usuarios. Por reseña histórica decir que en 2008 Sun
compró a MySQL que era una BD Open Source y posteriormente en el 2009 Oracle
compró a Sun.
MySQL tiene licencia GPL pero también
tiene parte con uso comercial con una licencia privativa, además comentar que el desarrollo de este SGBD es en C. Por lo que
comenté en el primer párrafo ahora el control de MySQL lo lleva una empresa
privada que también lo patrocina. El mayor uso de MySQL está en la web por ejemplo:
Wikipedia, Google, Facebook, Twitter, Flickr y Youtube entre otros.
Después de esta pequeña introducción voy
a pasar a detallar como se instala MySQL.
1.- Lo primero es ir a la página http://www.mysql.com/ en ella tendremos que ir al apartado de descargas (Downloads).
Como no me quiero gastar un duro en ello hay que ir al apartado que pone MySQL Community Edition (GPL) pulsamos en el link

y posteriormente vamos al apartado MySQL Workbech accediendo al DOWNLOAD que encontramos justo debajo.
 Tras hacer esto accedemos a una nueva pantalla, en dicha pantalla podemos ver que en la parte de abajo nos da a elegir como queremos descargar el MySQL Workbech en mi caso voy a elegir la versión no instalable y para Windows. Nota: No hace falta registrarse ni logearse puedes hacerlo entrando en "No thanks, just start my download". A continuación, tendremos un archivo .zip descargado en el escritorio o donde lo hayamos guardado.
Tras hacer esto accedemos a una nueva pantalla, en dicha pantalla podemos ver que en la parte de abajo nos da a elegir como queremos descargar el MySQL Workbech en mi caso voy a elegir la versión no instalable y para Windows. Nota: No hace falta registrarse ni logearse puedes hacerlo entrando en "No thanks, just start my download". A continuación, tendremos un archivo .zip descargado en el escritorio o donde lo hayamos guardado.

2.- El siguiente paso es obvio, tenemos que descomprimir el paquete, de todas formas lo digo por si acaso XD.

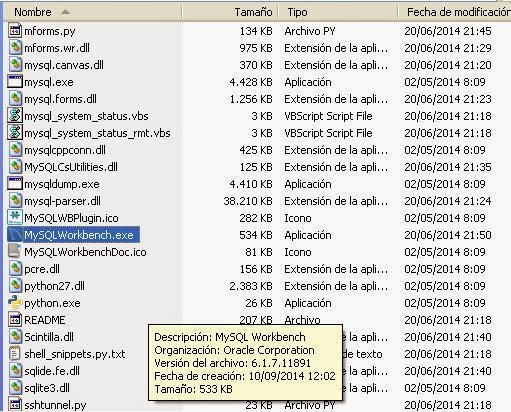
3.- Para ejecutarlo tenemos que ir al .exe y con ello ya hemos entrado en el MySQL.

1.- Lo primero es ir a la página http://www.mysql.com/ en ella tendremos que ir al apartado de descargas (Downloads).
Como no me quiero gastar un duro en ello hay que ir al apartado que pone MySQL Community Edition (GPL) pulsamos en el link
y posteriormente vamos al apartado MySQL Workbech accediendo al DOWNLOAD que encontramos justo debajo.
3.- Para ejecutarlo tenemos que ir al .exe y con ello ya hemos entrado en el MySQL.
En alguna entrada os comentaré como crear una BBDD con el MySQL creo que de lo siguiente que voy a hablar será de la ingeniería inversa que he visto interés en alguno de vuestros comentarios.







